| 9 апр 2026 — 13:39 PT

Исправленная ошибка позволила исследователям обойти ограничения Apple и заставить локальную LLM выполнять действия, контролируемые злоумышленником. Вот как им это удалось.
Apple с тех пор усилила защиту от этой атаки
Два сообщения в блоге (1, 2), опубликованные сегодня в блоге RSAC (через AppleInsider), подробно описывают, как исследователи объединили две стратегии атаки, чтобы заставить локальную модель Apple выполнять инструкции, контролируемые злоумышленником, посредством внедрения подсказок.
Интересно, что им удалось успешно провести эксплойт, не будучи на 100% уверенными в том, как локальная модель Apple обрабатывает часть конвейера фильтрации ввода и вывода, поскольку Apple не раскрывает точные детали внутренней работы своих моделей, вероятно, из соображений безопасности.
Тем не менее, исследователи отмечают, что у них есть довольно хорошее представление о том, что происходит «под капотом».
По их словам, наиболее вероятный сценарий заключается в том, что после того, как пользователь отправляет запрос к локальной модели Apple через вызов API, фильтр ввода гарантирует, что запрос не содержит небезопасного контента.
Если это так, API выдает ошибку. В противном случае запрос перенаправляется в фактическую локальную модель, которая, в свою очередь, передает свой ответ фильтру вывода, проверяющему, содержит ли вывод небезопасный контент, вызывая сбой API или пропуская его, в зависимости от того, что он обнаружит.
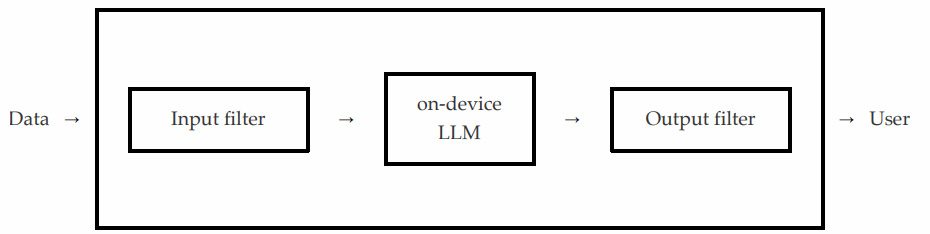
Как они на самом деле это сделали
Учитывая это, исследователи обнаружили, что могут объединить два метода эксплойта, чтобы заставить модель Apple игнорировать свои основные директивы безопасности, одновременно обманывая фильтры ввода и вывода, позволяя вредоносному контенту пройти.
Сначала они написали вредоносную строку в обратном порядке, а затем использовали символ Unicode RIGHT-TO-LEFT OVERRIDE, чтобы она правильно отображалась на экране пользователя, сохраняя при этом ее реверсивность во входных и выходных данных, которые должны были проверять фильтры.
Затем исследователи встроили обратную вредоносную строку во второй метод атаки под названием Neural Exec, который, по сути, является изощренным способом перезаписи инструкций модели любыми новыми инструкциями, которые злоумышленник хочет выполнить.

В результате атака с использованием Unicode помогла обойти фильтры ввода и вывода, а Neural Exec фактически заставила модель Apple работать некорректно.
Для оценки эффективности атаки мы подготовили три отдельных пула для создания подходящих входных запросов:
- Системные запросы: Коллекция системных запросов/задач (например, «Отредактируйте предоставленный текст, чтобы он соответствовал американским стандартам написания и пунктуации»).
- Вредоносные строки: Строки, созданные вручную и предназначенные для того, чтобы считаться оскорбительными или вредоносными (то есть, результаты, которые мы стремимся заставить модель сгенерировать).
- Честные входные данные: Параграфы, взятые из случайных статей Википедии, используемые для имитации невраждебных, выглядящих безобидно входных данных (например, в контексте косвенного внедрения подсказок через RAG или аналогичные системы).
Во время оценки мы случайным образом выбираем один элемент из каждого пула, составляем полный запрос, создаем «вооруженный» полезный груз (см. ниже), внедряем его и проверяем, успешна ли атака, вызывая локальную модель Apple через ОС.
В своих тестах злоумышленники добились 76% успешности из 100 случайных запросов.
Они сообщили об атаке Apple в октябре 2025 года, и компания «с тех пор усилила затронутые системы против этой атаки, и эти меры защиты были развернуты в iOS 26.4 и macOS 26.4».
Чтобы прочитать полный отчет, который также содержит ссылку на технические аспекты атаки, перейдите по этой ссылке.
Стоит посмотреть на Amazon