| 9 февраля 2026 г. — 6:47 PT

Новая модель под названием VSSFlow использует креативную архитектуру для генерации звуков и речи с помощью единой унифицированной системы, демонстрируя передовые результаты. Посмотрите (и послушайте) некоторые демонстрации ниже.
Проблема
В настоящее время большинство моделей преобразования видео в звук (то есть моделей, обученных генерировать звуки из бесшумных видео) не очень хорошо справляются с генерацией речи. Аналогично, большинство моделей преобразования текста в речь не могут генерировать неречевые звуки, поскольку они предназначены для других целей.
Кроме того, предыдущие попытки унифицировать обе задачи часто основывались на предположении, что совместное обучение снижает производительность, что приводило к настройкам, при которых речь и звук обучались на отдельных этапах, что усложняло конвейер.
Учитывая эту ситуацию, три исследователя Apple вместе с шестью исследователями из Китайского университета Жэньминь разработали VSSFlow — новую модель ИИ, которая может генерировать как звуковые эффекты, так и речь из бесшумного видео в рамках одной системы.
Более того, разработанная ими архитектура работает таким образом, что обучение речи улучшает обучение звука, и наоборот, вместо того, чтобы мешать друг другу.
Решение
Проще говоря, VSSFlow использует множество концепций генеративного ИИ, включая преобразование транскрипций в последовательности фонемных токенов и обучение восстановлению звука из шума с помощью потокового соответствия (flow-matching), о котором мы рассказывали здесь, по сути, обучая модель эффективно начинать с случайного шума и заканчивать желаемым сигналом.
Все это встроено в 10-слойную архитектуру, которая напрямую смешивает сигналы видео и транскрипции в процесс генерации аудио, позволяя модели обрабатывать как звуковые эффекты, так и речь в рамках единой системы.
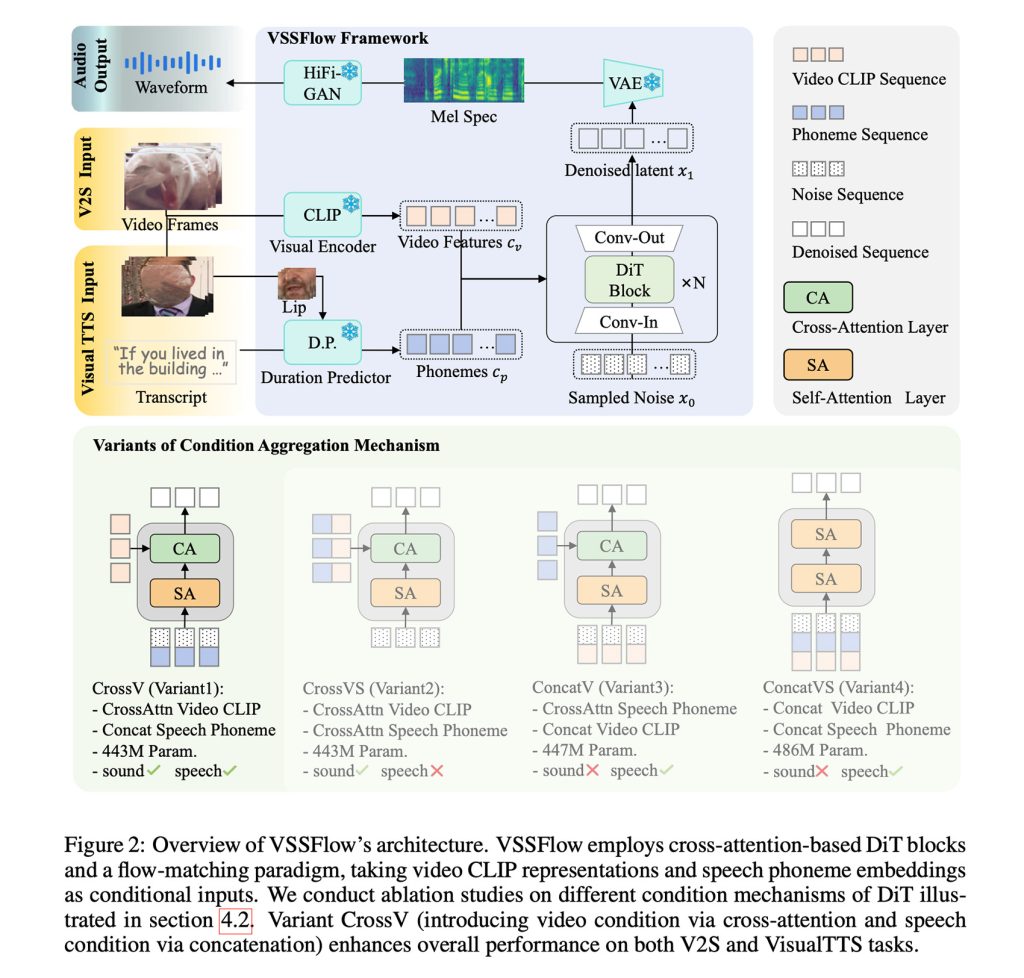
Что, возможно, более интересно, исследователи отмечают, что совместное обучение речи и звука на самом деле улучшило производительность в обеих задачах, вместо того чтобы вызывать конкуренцию или снижать общую производительность любой из задач.
Для обучения VSSFlow исследователи использовали модели, смешанные из бесшумных видео, сопряженных с окружающими звуками (V2S), бесшумных говорящих видео, сопряженных с транскрипциями (VisualTTS), и данных для преобразования текста в речь (TTS), позволяя ей одновременно изучать как звуковые эффекты, так и произнесенный диалог в рамках единого сквозного процесса обучения.
Важно отметить, что из коробки VSSFlow не могла автоматически генерировать фоновый звук и произнесенный диалог одновременно в одном выводе.
Для достижения этой цели они доработали уже обученную модель на большом наборе синтетических примеров, в которых речь и окружающие звуки были смешаны, чтобы модель научилась тому, как оба должны звучать одновременно.
Применение VSSFlow
Для генерации звука и речи из бесшумного видео модель начинает со случайного шума и использует визуальные подсказки, взятые из видео с частотой 10 кадров в секунду, для формирования окружающих звуков. Одновременно транскрипция произносимого текста обеспечивает точное руководство для генерируемого голоса.
При тестировании на моделях, специфичных для конкретных задач, созданных только для звуковых эффектов или только для речи, VSSFlow демонстрировала конкурентоспособные результаты в обеих задачах, лидируя по нескольким ключевым метрикам, несмотря на использование единой унифицированной системы.
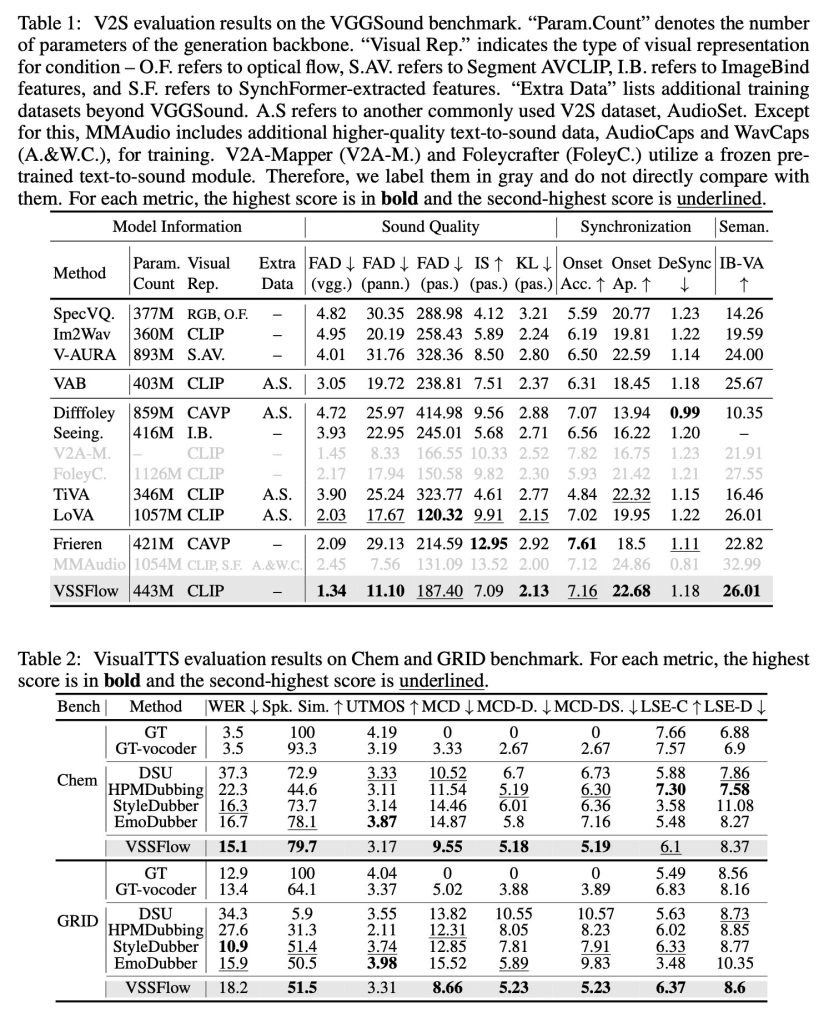
Исследователи опубликовали несколько демонстрационных результатов генерации звука, речи и совместной генерации (из видео Veo3), а также сравнения VSSFlow с несколькими альтернативными моделями. Вы можете посмотреть несколько результатов ниже, но обязательно перейдите на страницу с демонстрациями, чтобы увидеть их все.
И вот что действительно здорово: исследователи выложили код VSSFlow на GitHub и работают над тем, чтобы открыть веса модели. Кроме того, они работают над предоставлением демо-версии для вывода.
Что касается того, что может быть дальше, исследователи сказали:
Эта работа представляет собой унифицированную потоковую модель, объединяющую задачи преобразования видео в звук (V2S) и визуального преобразования текста в речь (VisualTTS), устанавливая новую парадигму для генерации звука и речи, обусловленной видео. Наша структура демонстрирует эффективный механизм агрегирования условий для включения речевых и видео условий в архитектуру DiT. Кроме того, мы выявляем взаимное стимулирующее влияние совместного обучения звука и речи посредством анализа, подчеркивая ценность унифицированной генеративной модели. Для будущих исследований существует несколько направлений, заслуживающих дальнейшего изучения. Во-первых, нехватка высококачественных данных для видео-речи-звука ограничивает разработку унифицированных генеративных моделей. Кроме того, разработка лучших методов представления звука и речи, которые могут сохранять детали речи, сохраняя при этом компактные размеры, является критически важной будущей задачей.
Чтобы узнать больше об исследовании под названием «VSSFlow: Unifying Video-conditioned Sound and Speech Generation via Joint Learning», перейдите по этой ссылке.
Скидки на аксессуары на Amazon