| 2 февраля 2026 г. — 16:04 PT

Группа исследователей Apple и Тель-Авивского университета нашла способ ускорить генерацию речи на основе ИИ без ущерба для разборчивости. Вот как они это сделали.
Интересный новый подход к более быстрой генерации речи
В новой статье под названием Principled Coarse-Grained Acceptance for Speculative Decoding in Speech (Принципиальное грубое принятие для спекулятивного декодирования речи) исследователи Apple подробно описывают интересный подход к генерации речи из текста.
Хотя в настоящее время существует несколько подходов к генерации речи из текста, исследователи сосредоточились на авторегрессионных моделях преобразования текста в речь, которые генерируют аудиотокены по одному за раз.
Если вы когда-либо изучали, как работают большинство больших языковых моделей, вы, вероятно, знакомы с авторегрессионными моделями, которые предсказывают следующий токен на основе всех предыдущих токенов.
Авторегрессионная генерация речи работает примерно так же, за исключением того, что токены представляют собой аудиофрагменты, а не слова или символы.
И хотя это эффективный способ генерации речи из текста, этот подход также создает «узкое место» в обработке, как объясняют исследователи Apple:
Однако для речевых LLM, генерирующих акустические токены, точное совпадение токенов является слишком ограничительным: многие дискретные токены акустически или семантически взаимозаменяемы, что снижает частоту принятия и ограничивает ускорение.
Другими словами, авторегрессионные речевые модели могут быть слишком строгими, часто отклоняя предсказания, которые были бы достаточно хороши, просто потому, что они не соответствуют точному токену, который ожидает модель. Это, в свою очередь, замедляет весь процесс.
Представляем Principled Coarse-Graining (PCG)
По сути, решение Apple основано на предположении, что множество различных токенов могут производить практически идентичные звуки.
Исходя из этого, Apple группирует речевые токены, звучащие похоже, создавая более гибкий этап проверки.
Другими словами, вместо того, чтобы рассматривать каждый возможный звук как совершенно отличный, подход Apple позволяет модели принимать токен, принадлежащий к той же общей группе «акустической схожести».
Фактически, PCG состоит из двух моделей: меньшей модели, которая быстро предлагает речевые токены, и второй, более крупной модели-судьи, которая проверяет, попадают ли эти токены в нужную акустическую группу, прежде чем принять их.
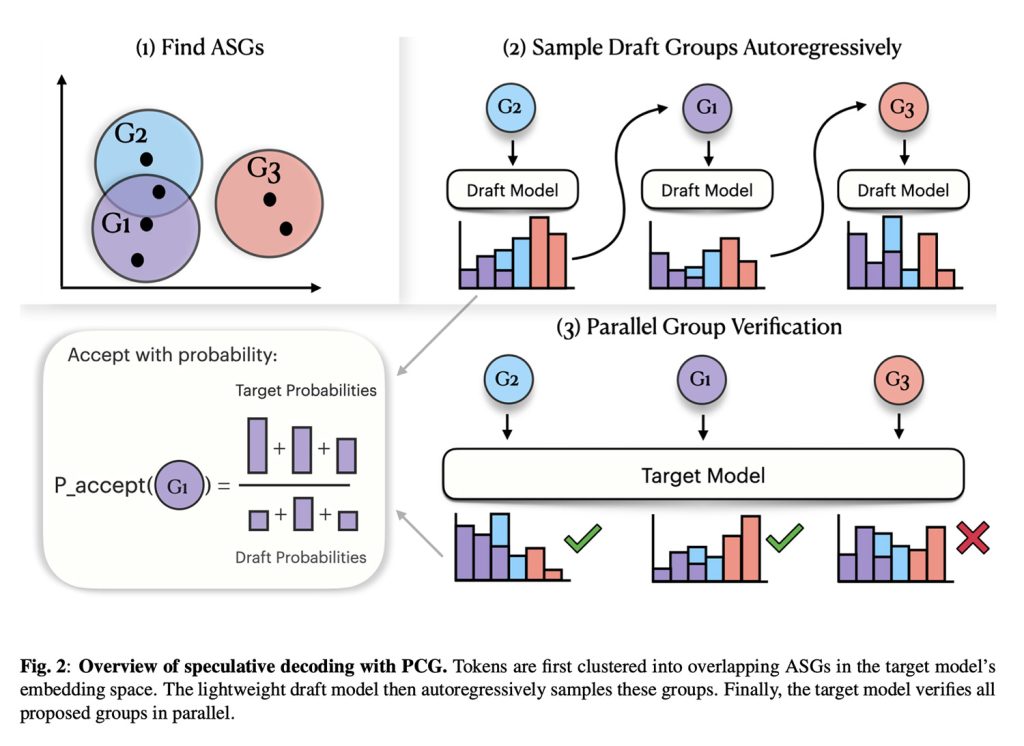
В результате получается фреймворк, который адаптирует концепции спекулятивного декодирования (SD) к LLM, генерирующим акустические токены, что, в свою очередь, ускоряет генерацию речи, обеспечивая при этом разборчивость.
И говоря о результатах, исследователи показывают, что PCG увеличил генерацию речи примерно на 40%, что является значительным улучшением, учитывая, что применение стандартного спекулятивного декодирования к речевым моделям почти не улучшило скорость.
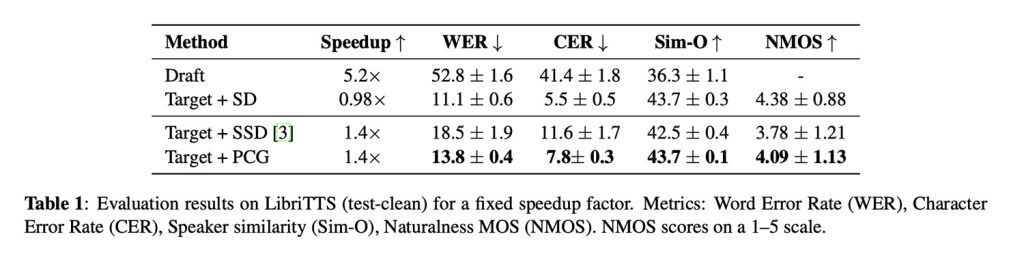
В то же время PCG поддерживал более низкие показатели ошибок по словам, чем предыдущие методы, ориентированные на скорость, сохранял схожесть говорящего и превосходил предыдущие методы, ориентированные на скорость, достигнув показателя естественности 4,09 (стандартная человеческая оценка от 1 до 5, насколько естественно звучит речь).
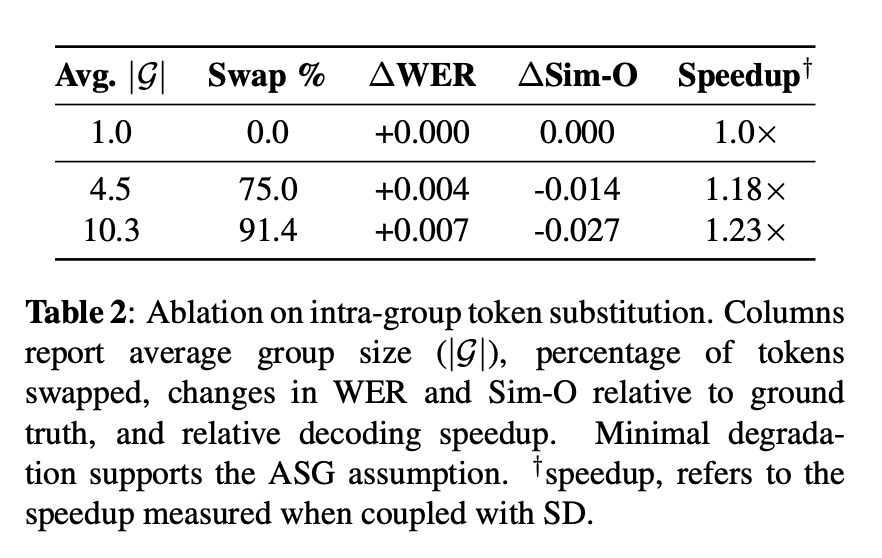
В одном стресс-тесте (Анализ подстановки токенов внутри группы) исследователи заменили 91,4% речевых токенов альтернативами из той же акустической группы, и аудио все еще выдерживало нагрузку, с увеличением частоты ошибок по словам всего на +0,007 и снижением схожести говорящего на −0,027:
Что PCG может означать на практике
Хотя в исследовании не обсуждается, что его выводы могут означать на практике для продуктов и платформ Apple, этот подход может быть актуален для будущих голосовых функций, которым необходимо сбалансировать скорость, качество и эффективность.
Важно отметить, что этот подход не требует обучения целевой модели, поскольку это изменение на этапе декодирования. Другими словами, это настройка, которую можно применить к существующим речевым моделям во время инференса, вместо того, чтобы требовать переобучения или изменения архитектуры.
Более того, PCG требует минимальных дополнительных ресурсов (всего около 37 МБ памяти для хранения групп акустической схожести), что делает его практичным для развертывания на устройствах с ограниченной памятью.
Чтобы узнать больше о PCG, включая подробные технические детали о наборах данных и дополнительный контекст о методах оценки, перейдите по этой ссылке.
Скидки на аксессуары на Amazon