| 14 янв 2026 — 12:44 pm PT

Исследователи Apple опубликовали исследование о Manzano — мультимодальной модели, которая объединяет понимание визуальной информации и генерацию изображений по текстовому описанию, при этом значительно снижая компромиссы в производительности и качестве, присущие текущим реализациям. Подробности — далее.
Интересный подход к решению передовой задачи
В исследовании под названием MANZANO: A Simple and Scalable Unified Multimodal Model with a Hybrid Vision Tokenizer команда из почти 30 исследователей Apple подробно описывает новый унифицированный подход, который позволяет одновременно понимать изображения и генерировать их по текстовому описанию в рамках одной мультимодальной модели.
Это важно, потому что современные унифицированные мультимодальные модели, поддерживающие генерацию изображений, часто сталкиваются с компромиссами: либо они жертвуют пониманием визуальной информации ради авторегрессивной генерации изображений, либо отдают приоритет пониманию, жертвуя при этом качеством генерации. Другими словами, им часто трудно преуспеть в обеих задачах одновременно.
Вот почему так происходит, по словам исследователей:
Ключевая причина этого разрыва заключается в противоречивой природе визуальной токенизации. Авторегрессивная генерация обычно предпочитает дискретные токены изображений, в то время как понимание обычно выигрывает от непрерывных вложений. Многие модели используют стратегию двойной токенизации, применяя семантический энкодер для получения богатых, непрерывных признаков, в то время как отдельный квантованный токенизатор, такой как VQ-VAE, обрабатывает генерацию. Однако это заставляет языковую модель обрабатывать два разных типа токенов изображения: один из высокоуровневого семантического пространства и один из низкоуровневого пространственного пространства, что создает значительный конфликт задач. Хотя некоторые решения, такие как Mixture-of-Transformers (MoT), могут смягчить это, выделяя отдельные пути для каждой задачи, они неэффективны с точки зрения параметров и часто несовместимы с современными архитектурами Mixture-of-Experts (MoE). Альтернативное направление работы обходит этот конфликт, замораживая предварительно обученную мультимодальную LLM и подключая ее к диффузионному декодеру. Хотя это сохраняет способность к пониманию, это разделяет генерацию, теряя потенциальные взаимные преимущества и ограничивая потенциальный прирост для генерации от масштабирования мультимодальной LLM.
Проще говоря, современные мультимодальные архитектуры не очень хорошо справляются с одновременным выполнением обеих задач, поскольку они полагаются на противоречивые визуальные представления для понимания и генерации, которые одна и та же языковая модель с трудом примиряет.
Вот тут-то и появляется Manzano. Он объединяет задачи понимания и генерации, используя авторегрессивную LLM для семантического предсказания того, что должно быть на изображении, а затем передает эти предсказания диффузионному декодеру (процесс шумоподавления, который мы объяснили здесь), который отрисовывает фактические пиксели.
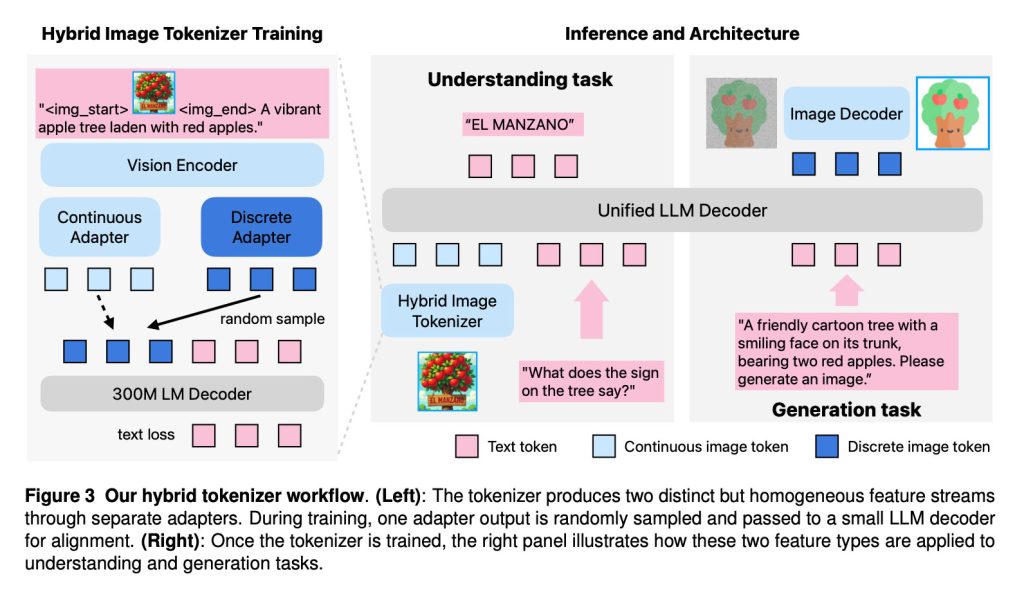
Как объясняют исследователи, Manzano объединяет три компонента в своей архитектуре:
- Гибридный токенизатор изображений, который производит как непрерывные, так и дискретные визуальные представления;
- LLM-декодер, который принимает текстовые токены и/или непрерывные вложения изображений и авторегрессивно предсказывает следующие дискретные токены изображения или текста из совместного словаря;
- Декодер изображений, который отрисовывает пиксели изображения из предсказанных токенов изображения
В результате этого подхода, «Manzano обрабатывает контринтуитивные, нарушающие законы физики запросы (например, «Птица летит под слоном») на уровне, сопоставимом с GPT-4o и Nano Banana», — говорят исследователи.

Исследователи также отмечают, что в различных тестах «модели Manzano 3B и 30B достигают превосходной или конкурентоспособной производительности по сравнению с другими передовыми унифицированными мультимодальными LLM».
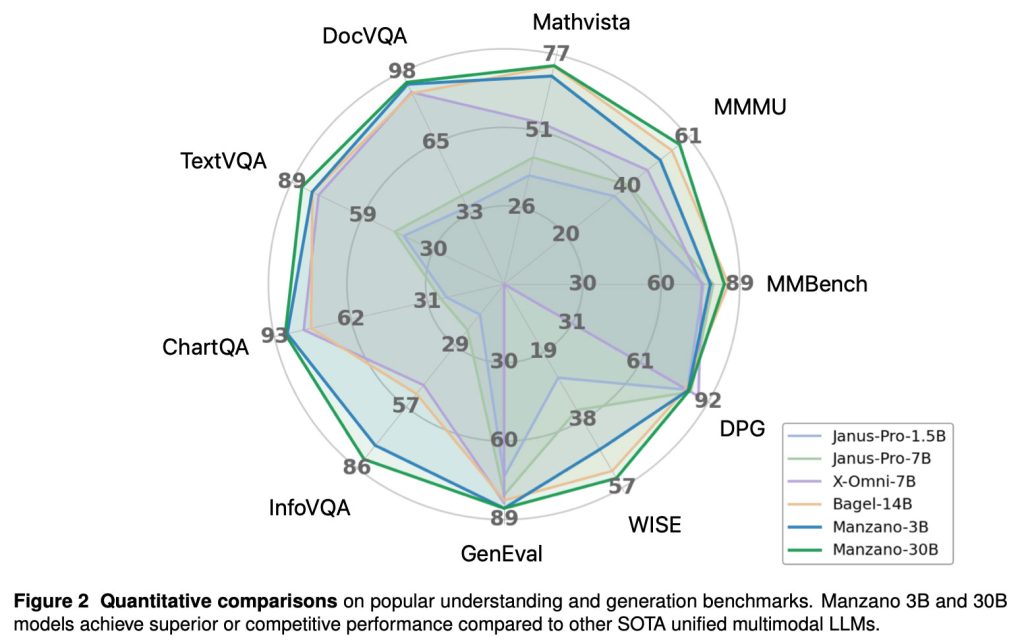
Исследователи Apple протестировали Manzano в различных масштабах — от модели с 300 миллионами параметров до версии с 30 миллиардами параметров. Это позволило им оценить, как улучшается унифицированная мультимодальная производительность по мере масштабирования модели:

Вот еще одно сравнение Manzano с другими передовыми моделями, включая Google Nano Banana и OpenAI GPT-4o:

Наконец, Manzano также хорошо показывает себя в задачах редактирования изображений, включая редактирование по инструкциям, перенос стиля, вставку/дорисовку и оценку глубины.

Чтобы ознакомиться с полным исследованием, содержащим подробные технические детали обучения гибридного токенизатора Manzano, дизайна диффузионного декодера, экспериментов по масштабированию и человеческих оценок, перейдите по этой ссылке.
И если вас интересует эта тема, обязательно ознакомьтесь с нашим объяснением UniGen — еще одной многообещающей моделью изображений, которую недавно представили исследователи Apple. Хотя ни одна из этих моделей не доступна на устройствах Apple, они свидетельствуют о продолжающейся работе над улучшением собственных результатов Apple в области генерации изображений в Image Playground и за его пределами.
Акции на аксессуары на Amazon