| 18 декабря 2025 г. — 12:29 PT

Опираясь на предыдущую модель под названием UniGen, команда исследователей Apple представляет UniGen 1.5 — систему, которая может обрабатывать понимание, генерацию и редактирование изображений в рамках одной модели. Вот подробности.
Развитие оригинального UniGen
В мае прошлого года команда исследователей Apple опубликовала исследование под названием UniGen: Enhanced Training & Test-Time Strategies for Unified Multimodal Understanding and Generation.
В этой работе они представили унифицированную мультимодальную большую языковую модель, способную как к пониманию, так и к генерации изображений в рамках одной системы, вместо использования отдельных моделей для каждой задачи.
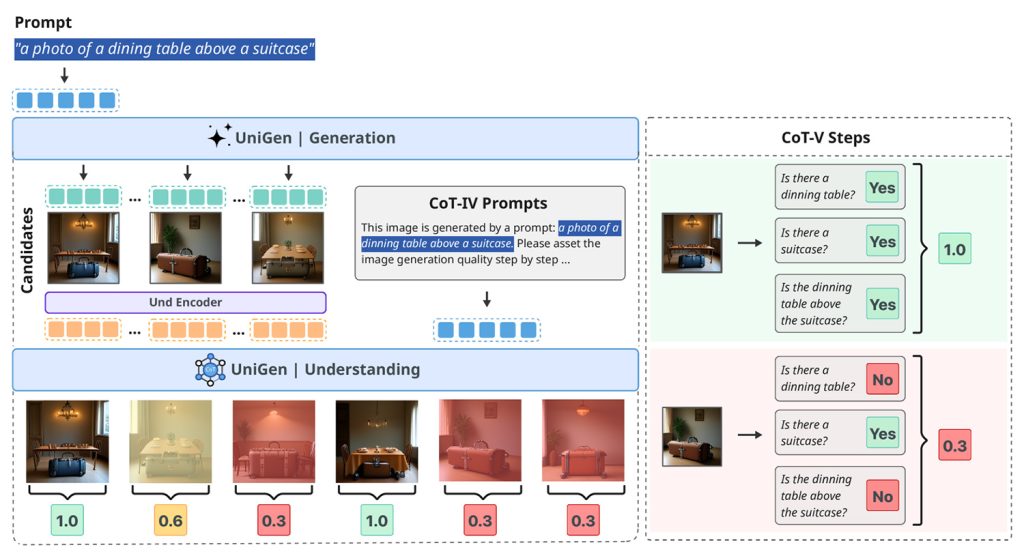
Теперь Apple опубликовала продолжение этого исследования в статье под названием UniGen-1.5: Enhancing Image Generation and Editing through Reward Unification in Reinforcement Learning.
UniGen-1.5, пояснение
Это новое исследование расширяет UniGen, добавляя возможности редактирования изображений в модель, по-прежнему в рамках единой унифицированной структуры, вместо разделения понимания, генерации и редактирования между различными системами.
Унификация этих возможностей в одной системе является сложной задачей, поскольку понимание и генерация изображений требуют разных подходов. Однако исследователи утверждают, что унифицированная модель может использовать свои способности к пониманию для повышения производительности генерации.
По их словам, одна из основных проблем при редактировании изображений заключается в том, что модели часто испытывают трудности с полным пониманием сложных инструкций по редактированию, особенно когда изменения незначительны или очень специфичны.
Для решения этой проблемы UniGen-1.5 вводит новый этап после обучения под названием «Выравнивание инструкций по редактированию»:
«Кроме того, мы наблюдаем, что модель остается неадекватной в обработке разнообразных сценариев редактирования после контролируемой дообучения из-за недостаточного понимания инструкций по редактированию. Поэтому мы предлагаем «Выравнивание инструкций по редактированию» как легкий этап Post-SFT для улучшения выравнивания между инструкцией по редактированию и семантикой целевого изображения. В частности, он принимает kondisiрующее изображение и инструкцию в качестве входных данных и оптимизируется для предсказания семантического содержания целевого изображения посредством текстовых описаний. Экспериментальные результаты показывают, что этот этап весьма полезен для повышения производительности редактирования».
Другими словами, прежде чем просить модель улучшить свои результаты с помощью обучения с подкреплением (которое тренирует модель, вознаграждая лучшие результаты и наказывая худшие), исследователи сначала обучают ее выводить подробное текстовое описание того, что должно содержаться в отредактированном изображении, на основе исходного изображения и инструкции по редактированию.
Этот промежуточный этап помогает модели лучше усвоить намеченное редактирование перед генерацией окончательного изображения.
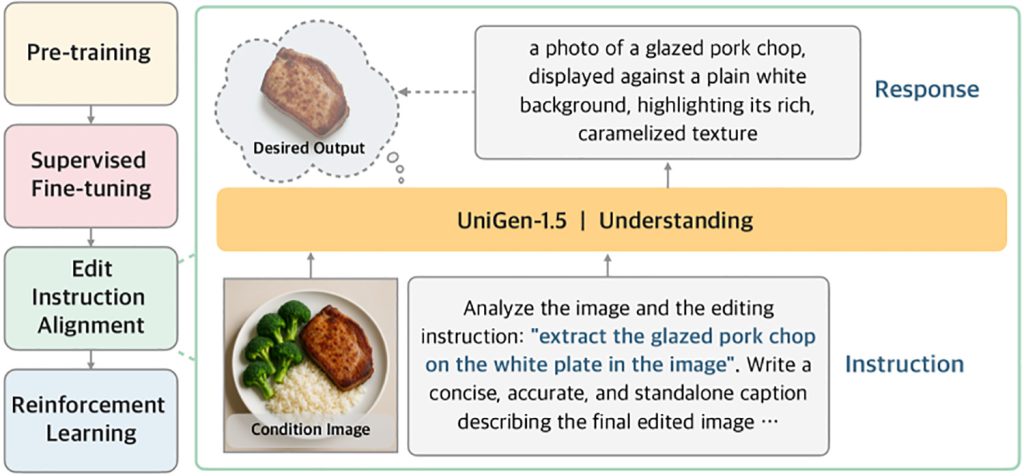
Затем исследователи используют обучение с подкреплением таким образом, который, возможно, является наиболее важным вкладом этой статьи: они используют одну и ту же систему вознаграждения как для генерации изображений, так и для их редактирования, что раньше было сложной задачей, поскольку правки могут варьироваться от незначительных корректировок до полных трансформаций.
В результате, при тестировании на нескольких отраслевых эталонных тестах, измеряющих, насколько хорошо модели следуют инструкциям, сохраняют визуальное качество и обрабатывают сложные правки, UniGen-1.5 либо соответствует, либо превосходит несколько передовых открытых и проприетарных мультимодальных больших языковых моделей:
Благодаря вышеупомянутым усилиям, UniGen-1.5 предоставляет более сильную базу для продвижения исследований в области унифицированных MLLM и демонстрирует конкурентоспособную производительность на эталонах понимания, генерации и редактирования изображений. Экспериментальные результаты показывают, что UniGen-1.5 получает 0,89 и 86,83 на GenEval и DPG-Bench соответственно, значительно превосходя последние методы, такие как BAGEL и BLIP3o. Для редактирования изображений UniGen-1.5 достигает общего балла 4,31 на ImgEdit, превосходя последние модели с открытым исходным кодом, такие как OminiGen2, и сравниваясь с проприетарными моделями, такими как GPT-Image-1.
Вот несколько примеров генерации изображений по текстовому описанию и возможностей редактирования изображений UniGen-1.5 (к сожалению, исследователи, похоже, ошибочно обрезали подсказки для сегмента «Текст-в-изображение» на первом изображении):

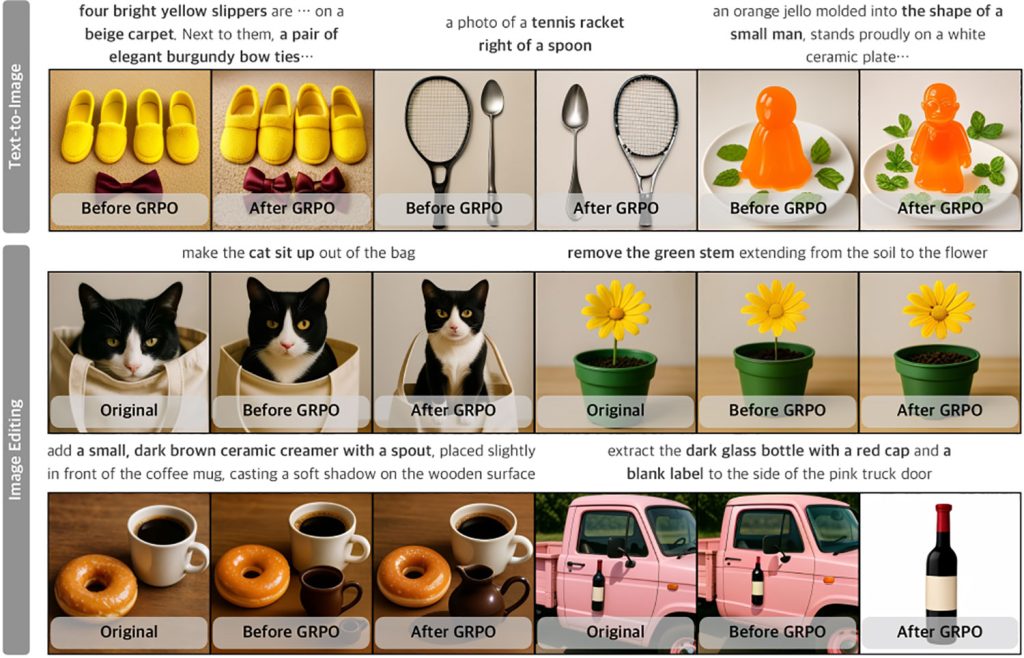
Исследователи отмечают, что UniGen-1.5 испытывает трудности с генерацией текста, а также с сохранением идентичности при определенных обстоятельствах:
Примеры неудач UniGen-1.5 как в задачах генерации текста в изображение, так и в редактировании изображений проиллюстрированы на Рисунке A. В первой строке мы представляем случаи, когда UniGen-1.5 не удается точно отобразить текстовые символы, поскольку легкий дискретный детокенизатор испытывает трудности с контролем мелкозернистых структурных деталей, необходимых для генерации текста. Во второй строке мы показываем два примера с видимыми изменениями идентичности, выделенными кругом, например, изменения в текстуре и форме шерсти кошки, а также различия в цвете оперения птицы. UniGen-1.5 нуждается в дальнейшем совершенствовании для устранения этих ограничений.

Полное исследование можно найти здесь.
Скидки на аксессуары на Amazon