| 9 декабря 2025 г. — 16:39 PT

Новое исследование, проведенное учеными из MIT и Empirical Health, использовало 3 миллиона человеко-дней данных Apple Watch для разработки базовой модели, которая с впечатляющей точностью предсказывает медицинские состояния. Вот детали.
Краткая справка
Когда Ян ЛеКун еще был главным научным сотрудником Meta по ИИ, он предложил Joint-Embedding Predictive Architecture, или JEPA, которая, по сути, учит ИИ выводить значение недостающих данных, а не сами данные.
Другими словами, при работе с пропусками в данных модель учится предсказывать, *что представляют собой* недостающие части, а не пытаться угадать и реконструировать их точные значения.
Например, для изображения, где некоторые части замаскированы, а другие видны, JEPA встраивает как видимые, так и замаскированные области в общее пространство (отсюда Joint-Embedding) и заставляет модель выводить представление замаскированной области из видимого контекста, а не точное *содержимое*, которое было скрыто.
Вот как Meta описала это, когда компания выпустила модель под названием I-JEPA в 2023 году:
В прошлом году главный научный сотрудник Meta по ИИ Ян ЛеКун предложил новую архитектуру, призванную преодолеть ключевые ограничения даже самых передовых систем ИИ на сегодняшний день. Его видение — создать машины, которые могут учиться внутренним моделям того, как устроен мир, чтобы они могли учиться гораздо быстрее, планировать выполнение сложных задач и легко адаптироваться к незнакомым ситуациям.
С момента публикации оригинального исследования JEPA ЛеКуна эта архитектура стала основой для области, изучающей «мировые модели», что является отходом от фокусировки на предсказании токенов, присущей LLM и системам на основе GPT.
Фактически, ЛеКун недавно покинул Meta, чтобы основать компанию, полностью посвященную мировым моделям, которые, по его мнению, являются истинным путем к AGI.
Итак, 3 миллиона дней данных Apple Watch?
Да, вернемся к текущему исследованию. Опубликованная несколько месяцев назад статья JETS: A Self-Supervised Joint Embedding Time Series Foundation Model for Behavioral Data in Healthcare была недавно принята к публикации на семинаре NeurIPS.
Она адаптирует подход совместного встраивания JEPA к нерегулярным многомерным временным рядам, таким как долгосрочные данные носимых устройств, где частота сердечных сокращений, сон, активность и другие измерения появляются непоследовательно или с большими пробелами с течением времени.
Из исследования:
В исследовании используется продольный набор данных, включающий данные носимых устройств, собранные от когорты из 16 522 человек, общей продолжительностью около 3 миллионов человеко-дней. Для каждого человека записывались 63 различных временных ряда метрик с ежедневным или более низким разрешением. Эти метрики были разделены на пять физиологических и поведенческих доменов: сердечно-сосудистое здоровье, респираторное здоровье, сон, физическая активность и общая статистика.
Интересно, что только у 15% участников были задокументированы медицинские истории для оценки, что означает, что 85% данных были бы непригодны для использования в традиционных подходах контролируемого обучения. Вместо этого JETS сначала обучался на полном наборе данных посредством самоконтролируемого предварительного обучения, а *затем* дообучался на размеченном подмножестве.
Чтобы все это заработало, они составили триплеты данных из наблюдений, соответствующих дню, значению и типу метрики.
Это позволило им преобразовать каждое наблюдение в токен, который, в свою очередь, прошел процесс маскирования, был закодирован, а затем подан на вход предсказателю (для предсказания встраивания отсутствующих участков).
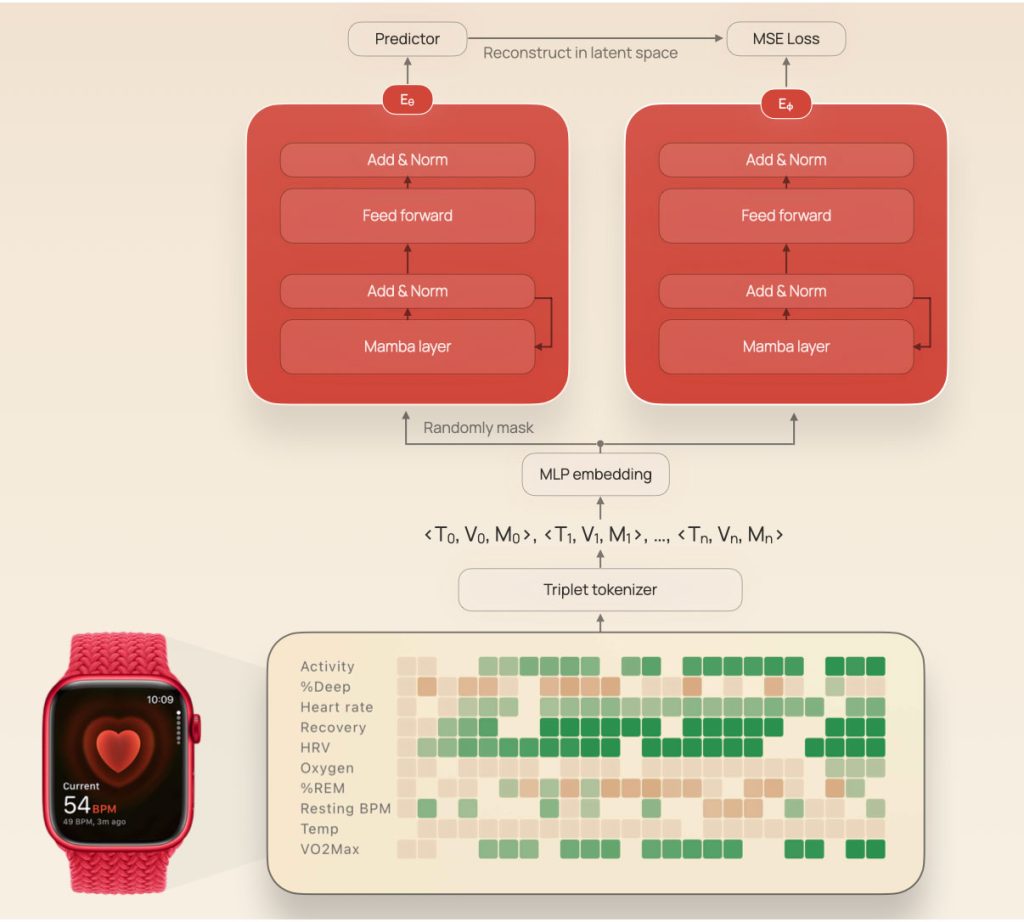
После этого исследователи сравнили JETS с другими базовыми моделями (включая предыдущую версию JETS на основе архитектуры Transformer) и оценили их с помощью AUROC и AUPRC, двух стандартных показателей того, насколько хорошо ИИ различает положительные и отрицательные случаи.
JETS достиг AUROC 86,8% для высокого кровяного давления, 70,5% для предсердной экстрасистолии, 81% для синдрома хронической усталости, 86,8% для синдрома слабости синусового узла и других. Конечно, он не *всегда* выигрывал, но преимущества вполне очевидны, как показано ниже:
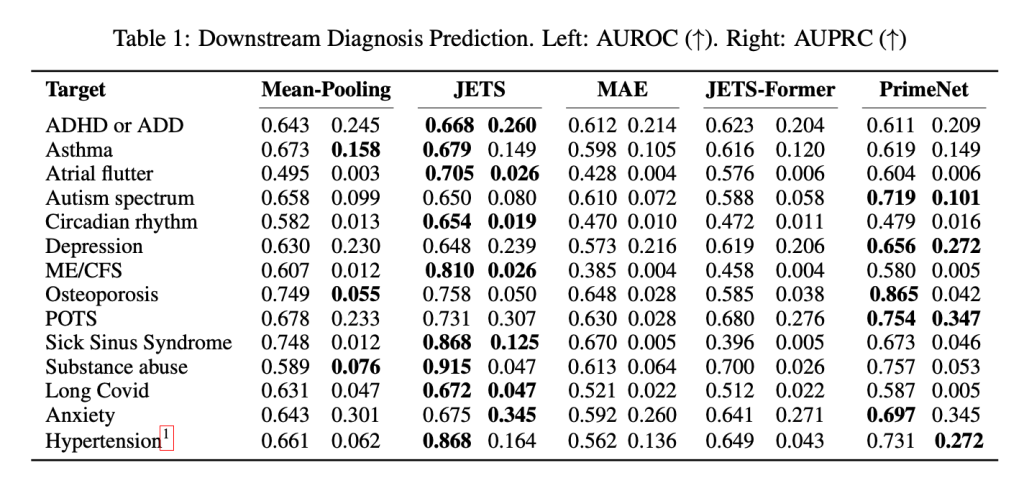
Стоит подчеркнуть, что AUROC и AUPRC — это не строго *индексы точности*. Это метрики, которые показывают, насколько хорошо модель ранжирует или приоритизирует вероятные случаи, а не то, как часто она дает правильные прогнозы.
В целом, это исследование представляет собой интересный подход к максимизации пользы и потенциала для спасения жизней данных, которые можно было бы списать как неполные или нерегулярные. В некоторых случаях показатели здоровья записывались только в 0,4% случаев, в то время как другие встречались в 99% ежедневных показаний.
Исследование также подкрепляет идею о том, что существует большой потенциал в новых моделях и методах обучения для анализа данных, которые уже собираются обычными носимыми устройствами, такими как Apple Watch, даже когда они не носятся 100% времени.
Полное исследование можно прочитать здесь.
Аксессуары со скидками на Amazon