| 4 июля 2025 г. — 8:53 PT

Apple незаметно представила новую AI-модель на Hugging Face с интересной особенностью. Вместо того чтобы писать код, как традиционные LLM генерируют текст (слева направо, сверху вниз), она может писать его и в произвольном порядке, улучшая несколько фрагментов одновременно.
Результат — более быстрая генерация кода с производительностью, соперничающей с ведущими моделями для написания кода с открытым исходным кодом. Вот как это работает.
Технические детали
Вот несколько (слишком упрощенных, ради эффективности) концепций, которые важно понять, прежде чем двигаться дальше.
Авторегрессия
Традиционно большинство LLM являются авторегрессионными. Это означает, что когда вы задаете им вопрос, они обрабатывают весь ваш запрос, предсказывают первый токен ответа, повторно обрабатывают весь запрос с первым токеном, предсказывают второй токен и так далее. Это заставляет их генерировать текст так же, как большинство из нас читает: слева направо, сверху вниз.
Температура
У LLM есть настройка, называемая температурой, которая контролирует степень случайности вывода. При предсказании следующего токена модель присваивает вероятности всем возможным вариантам. Более низкая температура делает более вероятным выбор наиболее вероятного токена, в то время как более высокая температура дает больше свободы для выбора менее вероятных.
Диффузия
Альтернативой авторегрессионным моделям являются диффузионные модели, которые чаще используются моделями изображений, такими как Stable Diffusion. В двух словах, модель начинает с размытого, зашумленного изображения и итеративно удаляет шум, учитывая запрос пользователя, направляя его к чему-то, что все больше и больше похоже на то, что запросил пользователь.

Все еще с нами? Отлично!
В последнее время некоторые большие языковые модели стали использовать диффузионную архитектуру для генерации текста, и результаты были весьма многообещающими. Если вы хотите глубже изучить, как это работает, вот отличное объяснение:
Почему я рассказываю вам все это? Потому что теперь вы можете понять, почему диффузионные модели текста могут быть быстрее авторегрессионных, поскольку они, по сути, могут (опять же, по сути) итеративно улучшать весь текст параллельно.
Такое поведение особенно полезно для программирования, где глобальная структура важнее линейного предсказания токенов.
Фух! Мы справились. Так что же выпустила Apple?
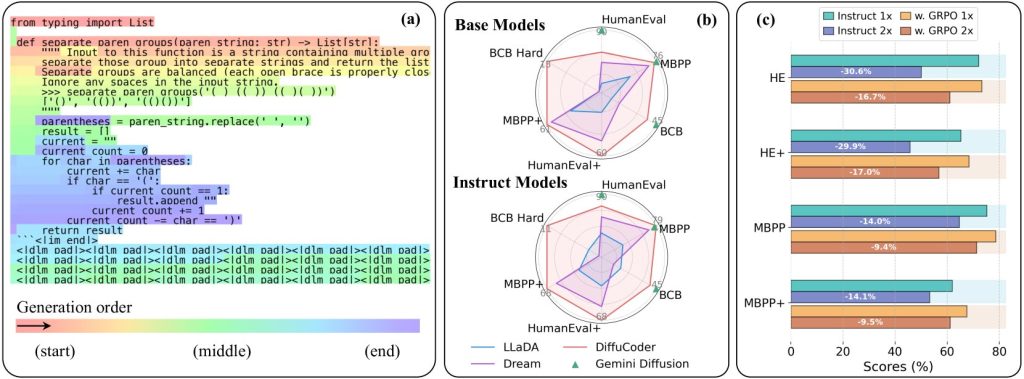
Да. Они выпустили модель с открытым исходным кодом под названием DiffuCode-7B-cpGRPO, которая основана на статье DiffuCoder: Understanding and Improving Masked Diffusion Models for Code Generation, опубликованной в прошлом месяце.
В статье описывается модель, которая использует диффузионный подход для генерации кода, но с одной особенностью:
«При увеличении температуры выборки с 0,2 по умолчанию до 1,2 DiffuCoder становится более гибким в порядке генерации токенов, освобождаясь от строгих ограничений слева направо»
Это означает, что, регулируя температуру, она может вести себя как авторегрессионная модель в большей или меньшей степени. По сути, более высокие температуры дают ей больше гибкости для генерации токенов в произвольном порядке, в то время как более низкие температуры удерживают ее ближе к строгому декодированию слева направо.
А благодаря дополнительному шагу обучения под названием coupled-GRPO она научилась генерировать более качественный код за меньшее количество проходов. Результат? Код, который генерируется быстрее, глобально согласован и конкурентоспособен с некоторыми из лучших моделей для программирования с открытым исходным кодом.
Основано на LLM с открытым исходным кодом от Alibaba
Что еще более интересно, модель Apple построена на основе Qwen2.5‑7B — фундаментальной модели с открытым исходным кодом от Alibaba. Alibaba сначала доработала эту модель для улучшения генерации кода (как Qwen2.5‑Coder‑7B), затем Apple взяла ее и внесла свои коррективы.
Они превратили ее в новую модель с диффузионным декодером, как описано в статье DiffuCoder, а затем снова доработали, чтобы она лучше следовала инструкциям. После этого они обучили еще одну ее версию, используя более 20 000 тщательно отобранных примеров кода.

И вся эта работа окупилась. DiffuCoder-7B-cpGRPO получила прирост на 4,4% в популярном бенчмарке кодирования и сохранила свою меньшую зависимость от генерации кода строго слева направо.
Конечно, есть много возможностей для улучшения. Хотя DiffuCoder показала лучшие результаты, чем многие диффузионные модели для кодирования (и это было до увеличения на 4,4% от DiffuCoder-7B-cpGRPO), она все же не достигает уровня GPT-4 или Gemini Diffusion.

И хотя некоторые отмечают, что 7 миллиардов параметров может быть ограничением, или что ее диффузионная генерация по-прежнему напоминает последовательный процесс, более важный момент заключается в следующем: шаг за шагом Apple закладывает основу для своих усилий в области генеративного ИИ, предлагая довольно интересные и новые идеи.
Перерастет ли это (или когда?) в реальные функции и продукты для пользователей и разработчиков — это уже другая история.
Скидки на AirPods на Amazon
- AirPods Pro 2, USB-C Charging: скидка 20% по цене $199
- AirPods (3rd Generation): скидка 20% по цене $134,99
- AirPods 4, USB-C and Wireless Charging: скидка 17% по цене $148,99
- AirPods 4 USB-C Charging: скидка 8% по цене $119
- AirPods Max Wireless, USB-C Charging, Midnight: скидка 13% по цене $479,99