| 12 мая 2025 г. — 14:59 по тихоокеанскому времени

В последние несколько месяцев ходило множество слухов и сообщений о планах Apple выпустить носимые устройства с поддержкой ИИ. В настоящее время, похоже, прямые конкуренты Apple для Meta Ray-Bans будут выпущены примерно в 2027 году, наряду с AirPods с камерами, которые предложат свой собственный набор функций с поддержкой ИИ.
Хотя, возможно, еще слишком рано говорить о том, как именно они будут выглядеть, Apple только что приоткрыла завесу над тем, как может работать их ИИ.
В 2023 году команда Apple по исследованиям в области машинного обучения выпустила MLX — собственную открытую ML-платформу, специально разработанную для Apple Silicon.
В двух словах, MLX предлагает легкий способ обучения и запуска моделей локально на устройствах Apple, оставаясь при этом знакомым для разработчиков, которые привыкли к фреймворкам и языкам, традиционно связанным с разработкой ИИ.
Новая визуальная модель Apple работает БЫСТРО
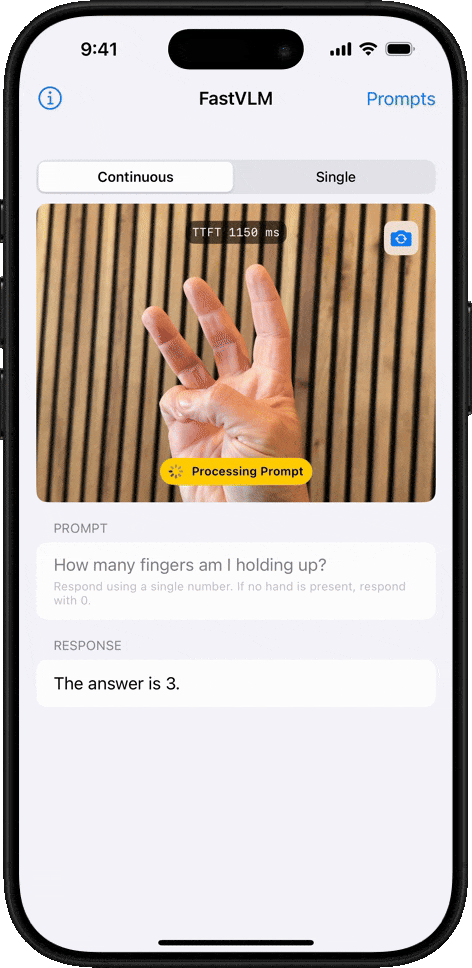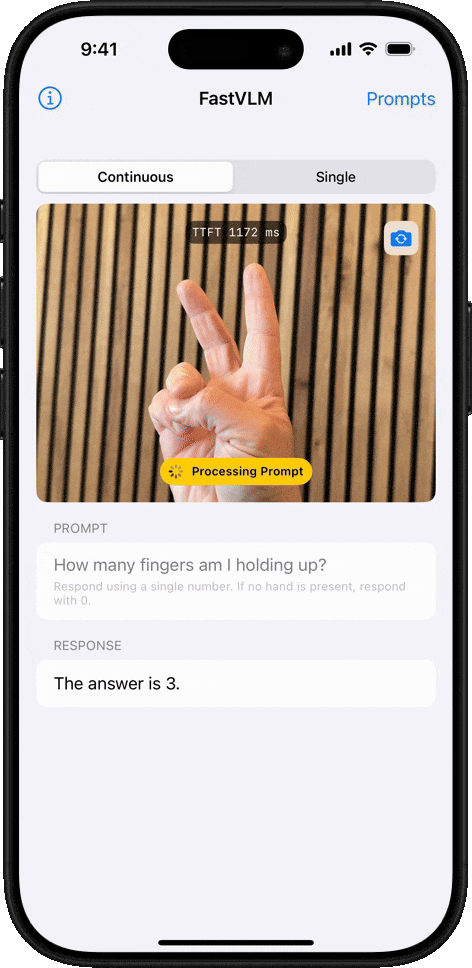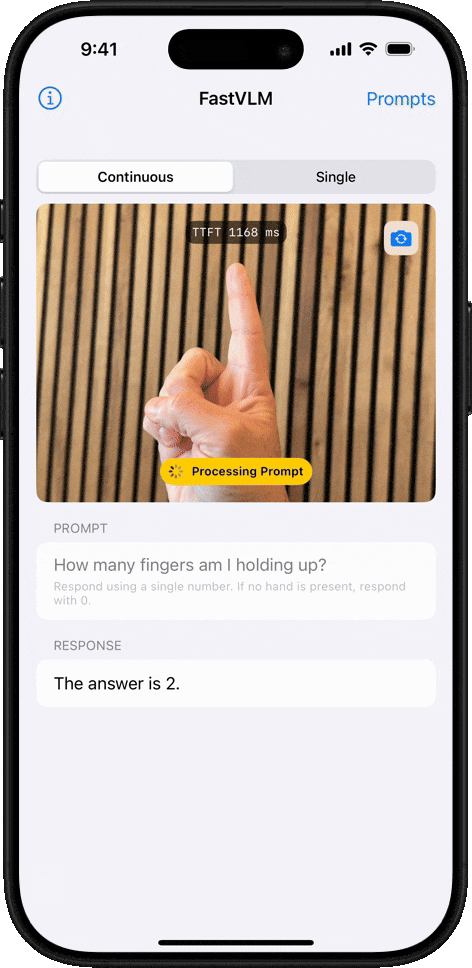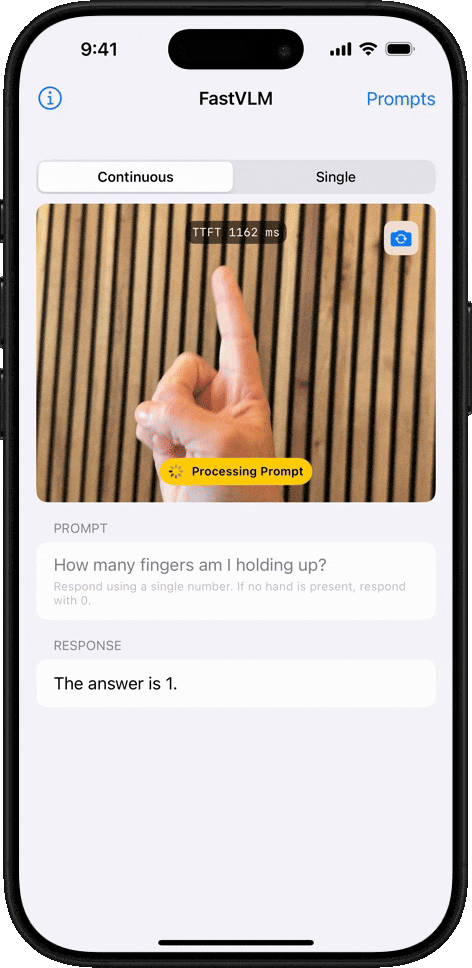

Теперь Apple выпустила FastVLM: визуальную языковую модель (VLM), которая использует MLX для обеспечения почти мгновенной обработки изображений высокого разрешения, требуя при этом значительно меньше вычислительной мощности, чем аналогичные модели. Как заявляет Apple:
Основываясь на всестороннем анализе эффективности взаимодействия между разрешением изображения, задержкой зрения, количеством токенов и размером LLM, мы представляем FastVLM — модель, которая достигает оптимизированного компромисса между задержкой, размером модели и точностью.
В основе FastVLM лежит кодировщик под названием FastViTHD. Этот кодировщик был «специально разработан для эффективной работы VLM с изображениями высокого разрешения».
Он до 3,2 раза быстрее и в 3,6 раза меньше аналогичных моделей. Это очень важно, если вы хотите, чтобы ваше устройство обрабатывало информацию локально, не полагаясь на облако для генерации ответа на то, что только что спросил пользователь (или на что он смотрит).
Кроме того, FastVLM был разработан для вывода меньшего количества токенов, что также является ключевым во время инференса — этапа, когда модель интерпретирует данные и генерирует ответ. По данным Apple, ее модель имеет в 85 раз более быстрое время до первого токена, чем аналогичные модели, то есть время, необходимое пользователю для отправки первого запроса и получения первого токена ответа. Меньшее количество токенов на более быстрой и легкой модели означает более быструю обработку.
FastVLM доступен на GitHub, а отчет можно найти на arXiv. Это нелегкое чтение, но оно определенно стоит того, если вы интересуетесь более техническими аспектами проектов Apple в области ИИ.